
Bridge the gap between fast computation and high accuracy with multi-fidelity response surface models
Written by Mariapia Marchi and Simone Genovese
28 February 2025 · 5 min read

Many engineering design applications involve computationally expensive simulations, such as Computational Fluid Dynamics (CFD) — a numerical method used to analyze fluid flow behavior — in the aerospace or automotive sectors or finite element methods for structural engineering. In some cases long physical experiments are also used to obtain the quantity of interest such as workbench tests in the mechanical sector. In these situations, even a design space exploration — let alone design space optimization — is often impracticable because the time needed for a single design evaluation is very long. For all these cases, surrogate models are an attractive option. Once an initial set of data is available, a surrogate model (or metamodel, or response surface model (RSM) in the modeFRONTIER software solution for process automation and design optimization) can be trained and used as a proxy of the expensive computer model or physical experiment. As a result, engineers can predict the values of new design configurations in almost zero time.
There are also cases where data from different information sources are available for a given quantity of interest, such as CFD responses obtained with a two- or a three-dimensional mesh, usually with different levels of fidelity. High-fidelity (HF) data are accurate, but also computationally expensive and available in a limited quantity. Low-fidelity (LF) simulations are less accurate, due to simplifications such as dimensionality reduction, linearization, use of simpler physics models, coarser domains or partially converged results, but they are also cheaper. Consequently, larger low-fidelity data sizes are affordable.
Consequently, multi-fidelity models provide a framework for fusing together information from the different data sources leveraging the strengths and correlation of the various models into a single model. The resulting multi-fidelity RSM has improved accuracy compared with a surrogate model built separately on the LF or HF data. Multi-fidelity models allow for accurate predictions while optimizing computational resources.
How the multi-fidelity RSM tool works in modeFRONTIER
The multi-fidelity model tool allows you to combine data from different sources, sizes, and fidelity into a single metamodel training. You can now create more accurate RSMs by integrating knowledge extracted from HF simulations with LF data, which are quick to generate but may lack precision. This integration ensures that models are both computationally efficient and reliable across varying fidelity levels.
The tool also facilitates incremental data collection and modeling. You can quickly collect LF data while performing expensive high-fidelity simulations or experiments and start training an LF model that you’ll complement with HF data as soon as available. This progressive approach shortens setup time and accelerates the overall modeling process.
You can even consider LF and HF tables with different sets of constant variables, for example because it’s more convenient to carry out the expensive experiment by fixing some sort of control variables that you can more easily vary with the LF simulations.
Correction-based and Co-Kriging methods
- Correction-Based Multi-Fidelity (CBMF) algorithm — applies to align low- and high-fidelity data, ensuring the model accounts for discrepancies between the two.
- Co-Kriging — a statistical approach that combines low- and high-fidelity datasets to improve prediction accuracy and provide mean-squared error estimates.

Correction-based methods are known to be simpler and more robust than Co-Kriging, which, in turn, is more accurate and provides estimates of mean-squared errors.
Two ways to train a multi-fidelity model
modeFRONTIER’s implementation of the two models caters to two types of users. Co-Kriging, with its simple user-interface, is designed for non-experts or users who prefer simplicity and automation, whereas CBMF is meant for practitioners who prefer to fully configure the tools themselves. Both algorithms address two scenarios:
- You have already trained an LF model with the modeFRONTIER RSM tool
- You want to train the multi-fidelity model in one go
In the first case, the multi-fidelity model is trained with an existing RSM model in the Design Space and an HF table of designs. In the second case, it’s trained with both an LF and HF table of designs. Therefore, the first scenario offers a wider choice of LF models and allows users to fully configure the low-fidelity RSM training parameters.
Application scenario: multi-fidelity RSM approach for engine control unit calibration
A key limitation in engine testing is that physical test bench evaluations are expensive and time-consuming. Moreover, for safety reasons and to avoid engine damage, it isn’t possible to test the engine in all operating conditions, especially at extreme regimes. Therefore, it’s essential to use simulation and develop predictive models that can accurately estimate system behavior in conditions that can’t be physically tested. These models are typically used to generate engine control unit (ECU) calibration maps, which play a critical role in optimizing engine performance, emissions, and fuel efficiency, making accuracy essential for robust engine control strategies.
However, when it comes to engineering simulation, the biggest challenge is balancing the accuracy of the simulation models and their computational costs. To address this limitation, we used modeFRONTIER simulation automation workflow and its multi-fidelity RSM tool to combine HF engine test bench data with LF simulations performed with GT-Suite multi-physics systems simulation software. LF models can’t achieve the required accuracy due to the inherent approximations of one-dimensional (1D) simulations, so HF data must be integrated for reliable predictions.
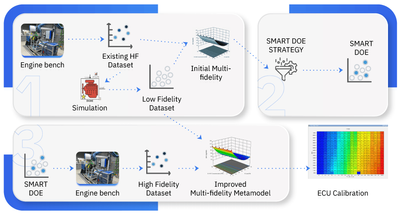
Multi-fidelity RSM approach for engine control unit calibration using modeFRONTIER
Building the multi-fidelity model
The following steps outline how we built, validated, and refined the multi-fidelity response surface model for engine calibration.
- Integrated GT-SUITE into modeFRONTIER to set up the simulation automation workflow for engine studies.
- Generated a low-fidelity (LF) dataset using DOE algorithms — 3,000 simulations.
- Merged datasets by combining the LF simulations with 45 high-fidelity (HF) test bench data points from an automotive OEM for metamodel training.
- Trained multi-fidelity RSMs in modeFRONTIER using Co-Kriging, creating one model per output: exhaust temperature, turbo speed limit, and maximum pressure.
- Validated the models using mean relative error and the distance chart to assess performance and coverage.
- Identified high-error regions in specific areas of the output domain.
- Refined the design space with modeFRONTIER’s Incremental Space Filler (ISF) DOE to add informative samples and improve model quality in those regions.
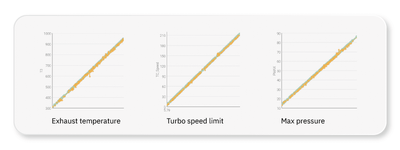
modeFRONTIER’s Co-Kriging distance charts of three different outputs
Results and performance improvements
With this approach, we successfully developed a multi-fidelity response surface model (RSM) that showed an average error rate reduced to less than 1%, achieving a 70% reduction compared to the low-fidelity RSM model. As a result, this substantial improvement in accuracy allowed us to minimize the number of evaluations required on the real engine bench, leading to considerable savings in both time and costs.
In conclusion, while 1D simulations offer a cost-effective and rapid method for initial engine analysis, relying solely on them can introduce inaccuracies that significantly impact critical design decisions. At the same time, physical testing, while providing valuable real-world data, is limited by substantial cost and safety constraints, especially when exploring extreme operating conditions. Therefore, the best approach path is to adopt a multi-fidelity approach that intelligently combines the strengths of both simulation and experimental data. This can be a key to a robust and efficient engine calibration process, ultimately leading to the development of more accurate and reliable ECU maps.
In conclusion
While 1D simulations offer a cost-effective and rapid method for initial engine analysis, relying solely on them can introduce inaccuracies that significantly impact critical design decisions. At the same time, physical testing, while providing valuable real-world data, is limited by substantial cost and safety constraints, especially when exploring extreme operating conditions. Therefore, the best approach path is to adopt a multi-fidelity approach that intelligently combines the strengths of both simulation and experimental data. This can be a key to a robust and efficient engine calibration process, ultimately leading to the development of more accurate and reliable ECU maps.
Key takeaways:
- Multi-fidelity modeling combines HF and LF data for accurate, cost-efficient predictions.
- modeFRONTIER offers two algorithms: Co-Kriging for automation and CBMF for full control.
- Incremental modeling improves accuracy as HF data becomes available.
- GT-SUITE integration accelerates simulation–test data exchange.
- Validation ensures reliable predictions across the design space.
- Multi-fidelity RSMs achieved <1% error and 70% accuracy improvement.
- The workflow reduces engine testing time and enhances ECU calibration.
People also ask
Multi-fidelity RSM models combine data from high-fidelity (HF) and low-fidelity (LF) sources to balance accuracy and computational cost. This allows engineers to achieve highly accurate predictions while significantly reducing the number of expensive simulations or experiments required.
Co-Kriging is best when accuracy and error estimation are top priorities, or when engineers want an automated, user-friendly setup. CBMF methods are better suited for users who prefer greater control and configuration flexibility when adjusting LF–HF correlations.
Yes. Low-fidelity datasets can often be reused or extended in future studies. modeFRONTIER allows users to import existing LF data tables and complement them with new HF data to train updated RSMs, accelerating subsequent design cycles.
modeFRONTIER’s multi-fidelity tool supports incremental modeling by enabling engineers to start with LF data and progressively add HF results as they become available. This approach continuously improves model accuracy without restarting the entire training process.
modeFRONTIER is the leading software solution for simulation process automation and design optimization.
Design better products faster
modeFRONTIER is the leading software solution for simulation process automation and design optimization.
Design better products faster
modeFRONTIER is the leading software solution for simulation process automation and design optimization.