
Enhancing AI sustainability in engineering design optimization with RSM and ROM
Written by Danilo Di Stefano and Alessandro Viola
30 March 2026

Artificial intelligence (AI) and machine learning (ML) are reshaping the landscape of engineering simulation by enhancing productivity and enabling data-driven decision making. But this digital revolution comes with a hidden physical cost: energy consumption.
The World Economic Forum estimates that the energy required to run AI tasks will grow by 26% to 36% annually over the next four years. For engineering design optimization - which relies on computationally intensive simulations to find optimal design performance configurations within constraints - this poses a significant sustainability challenge. How do we achieve engineering design excellence without creating an unsustainable environmental footprint?
The answer is to make simulation models smarter by employing AI/ML to create computationally efficient surrogate models that allows you to perform more rapid exploration of design spaces. This aligns closely with recent research by McKinsey & Company exploring how the engineering simulation will look like in 10-15 years. One of the key hypotheses is that there will not be distinct roles: the simulation engineer and the AI/ML engineer.
These roles are expected to merge by combining technical engineering expertise with skill to manage and run AI/ML tools. To make this happen, simulation engineers should be eager to integrate engineering knowledge of physics modeling with AI/ML expertise. To enable this shift, the AI data-driven modeling tools have to evolve to be both simplified and interoperable with the broad engineering numerical simulation ecosystem.
The AI/ML process data flow for rapid design predictions
At ESTECO, we propose an integrated AI/ML process data flow. This approach prioritizes the reuse of existing data to create surrogate models that accurately approximate physical behaviors instantly. By reusing relevant datasets from prior projects, we can substantially reduce the need for new simulations or experiments, thereby conserving computational resources. This not only improves sustainability but also accelerates the training and validation of AI/ML models within a process automation and design optimization framework such as modeFRONTIER.
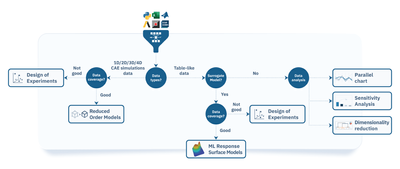
At the core of our approach lies the modeFRONTIER automated simulation workflow enhanced with design exploration and optimization techniques, providing you a unified backbone for processing both tabular and spatial data and generating computationally efficient surrogate models.
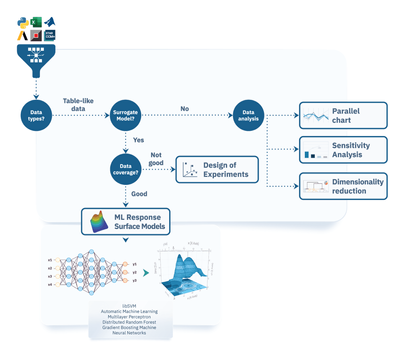
Table-like data
Table‑like data consist of numerical values that define different aspects of the design: input variables (such as dimensions, thickness, temperature, and material properties) and output variables that represent the system’s response (for example, maximum stress, drag coefficient, or heat transfer rate). This type of data is essential for statistical analysis and traditional machine learning modeling, including response surface models (RSM).
Spatio-temporal data
Spatio‑temporal data encompasses detailed representations of geometries and physical properties of objects in a design, along with their evolution over time. In the context of 1D/2D/3D/4D (time) computer‑aided engineering (CAE) simulations, spatio‑temporal data is essential for modeling and analyzing complex behaviors such as fluid flow, heat transfer, and structural deformation, among others. This type of data can be leveraged to build ML-based reduced order models (ROM).
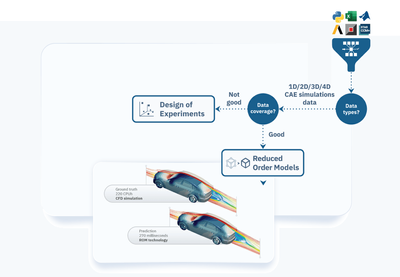
Build CAE datasets, train ROM, and predict design using modeFRONTIER’s automated workflow
Spatio‑temporal data plays a central role in engineering simulation by capturing the physical attributes of objects - such as their position, shape and orientation - within a given space. This data forms the foundation for various simulations, including computational fluid dynamics (CFD) and finite element analysis (FEA). While high-fidelity simulations deliver accurate results, they often come with significant costs in licenses, computational power, and storage requirements. As a result, they are typically limited to the pre-production phase due to these operational costs.
modeFRONTIER’s automated simulation workflow addresses this challenge by enabling the reuse of high-fidelity simulation data to train accurate AI/ML models much earlier in the conceptual design phase. AI/ML models such as ROM enhance complex simulations by scaling their interpretability and delivering more explainable results.
The main steps of the AI/ML process flow are as follows:
- Automated simulation: modeFRONTIER executes engineering solvers within its automated simulation workflow, ensuring consistent and repeatable execution of analyses across multiple design configurations.
- CAE dataset creation: modeFRONTIER applies its DOE algorithms to sample the design space and generate a database of CAE solutions.
- AI/ML training set creation: nD modeler app - integrated in modeFRONTIER - trains and tunes ML model parameters for ROM computation.
- ROM prediction: modeFRONTIER’s ROM prediction workflow enables rapid evaluation of hundreds of new designs to verify specific KPIs or constraints within an acceptable timeframe.
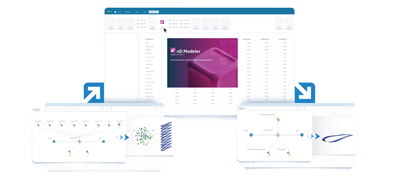
nD Modeler app: govern, play and test different AI/ML architectures
The nD Modeler app, the first addition to the new ESTECO’s nDAI platform for instant design predictions, is integrated in modeFRONTIER. It empowers you to architect different types of data-driven models, ranging from proper orthogonal decomposition (POD) to deep learning (DL). It is capable of modeling any type of engineering data, whether 0D parametric data, 1D curves or signals, 2D surface fields, or 3D simulations. You can train and tune ML model parameters specifically for engineering tasks such as vibrational, aerodynamics and thermal analysis to name a few. Then, compare models side-by-side in terms of accuracy and data consumption to select the optimal approach for your engineering design challenge.
Indeed, different engineering problems may require different ML architectures to deliver accurate predictions while limiting the consumption of data. Even for the same problem, multiple architectures can work, but feasibility depends on simulation data availability. nD Modeler answers critical questions through a guided approach for simulation engineers who don’t necessarily have a data science background: which model architecture fits my problem? Do I have enough training data? Should I use deep or shallow learning? What’s the accuracy-efficiency trade-off?
nD Modeler serves as the critical bridge in your AI/ML workflow, seamlessly linking upstream data preparation with downstream production deployment for design prediction. Once trained, the model seamlessly embeds into modeFRONTIER's prediction workflow. The surrogate of the 3D model replaces the CAE solver in a design optimization loop. This approach significantly enhances the efficiency of the design process while maintaining a high degree of accuracy.
Real-world impact: ROM industrial use case applications
In our recent ebook “The guide to AI data-driven design in modeFRONTIER”, we deep dive into how our technology has been applied in many industry sectors to replace time-intensive high-fidelity simulations with fast, data-driven surrogates without sacrificing accuracy. In the automotive sector, ROM can reduce aerodynamic analysis time by 88% and enable near-instant crash test predictions that traditionally require heavy computation.
The aerospace and marine industries leverage these AI/ML models to turn weeks of work into minutes, reducing transonic wing and propeller optimization cycles from hundreds of CPU hours to real-time evaluations. Furthermore, healthcare and electronics use ROM for complex devices such as blood pumps and microwave waveguides, achieving result accuracy within ~1% error while eliminating hours of solver time.

Download ebook
Key takeaways
- modeFRONTIER's automated simulation workflow stands as the unified backbone for seamlessly handling both tabular and spatio-temporal data to perform statistical analysis and gain richer insight into system behavior, to eventually improve initial DOE, and use it to build reliable surrogate models.
- Thanks to modeFRONTIER’s automated data‑flow capabilities, building AI and ML models becomes much faster and more streamlined: the tool handles data ingestion, processing, and model generation so you can focus on model validation and interpretation.
- The nD Modeler app plays a key role in modeFRONTIER. It lets you architect, train, and compare ML architectures (from POD to deep learning) for any data type (0D to 4D). Its guided interface answers key questions: which model fits? is data sufficient? what's the accuracy-efficiency trade-off?
- You can apply ESTECO’s physics-neutral ROM technology broadly across engineering design problems. It allows you to replace costly CAE solvers in optimization loops, reducing computational time while keeping meaningful predictive accuracy of surrogate models.
People also ask
Reduced Order Models (ROM) and Response Surface Models (RSM) are both surrogate models, but they serve different purposes. RSM typically works with structured, tabular data and statistical methods. However, ROM can handle complex spatio-temporal data from simulations like CFD or FEA, making it more suitable for high-dimensional engineering problems.
AI-based surrogate models like ROM can reduce simulation time from hours or days to seconds. Therefore, engineers can test more design options in less time and speed up the overall optimization process.
You should use AI surrogate models when you need fast predictions across many design variations. However, full simulations are still necessary for final validation or when very high accuracy is required.
Reliable AI models require high-quality simulation or experimental data. Ideally, this data should cover a wide range of design conditions to ensure the model can generalize and make accurate predictions.
Leverage modeFRONTIER’s AI/ML workflow automation for rapid design optimization early in product development.
The guide to AI data-driven design in modeFRONTIER
Leverage modeFRONTIER’s AI/ML workflow automation for rapid design optimization early in product development.
The guide to AI data-driven design in modeFRONTIER
Leverage modeFRONTIER’s AI/ML workflow automation for rapid design optimization early in product development.